
数据科学今年来变成越来越热的一个,最近在研究如何在产品开发中运用数据分析,这篇文章主要分享一些我的理解,希望有些实际意义。
图1被称为大数据的文氏图,总结了做数据科学分析需要的技能集合。这张图表面上看起来很容易懂,一个好的数据科学分析要求个人或者团队必须得有三个方面的技能:统计学知识,程序开发能力,行(专)业知识。但是深挖一些,为什么统计学和开发结合就变成机器学习,统计学和专业知识结合就变成传统研究方式,专业知识和编程能力的结合是危险区域,而为什么所谓的“数据科学”需要三者兼备本文主要用具体的例子对这几个知识技能之间的关系做一个解释。
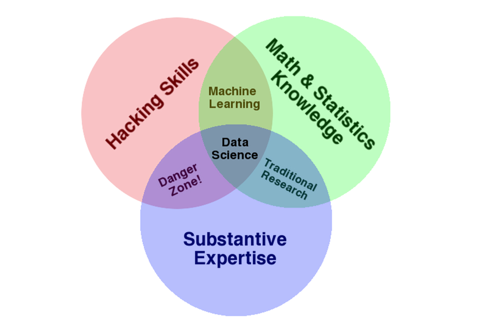
图1:数据分析文氏图
统计学在数据分析中的应用
统计学的知识是做数据分析不可缺少的一部分。大部分的知识可能很多人已经还给大学老师了,我在这里举出一个例子关于如何运用统计理论做数据分析,希望能够唤起一些兴趣。
我的例子当中用到的理论有二项分类法(binary classification)和混淆矩阵,名字听起来很厉害,慢慢看,其实很简单,我们说故事,尽量不提公式。
1940年秋到1941年中,作为闪电战的一部分,大量德国战机对英国进行轰炸。在20世纪40年代初,雷达仍是一个正在研发中的绝密技术。英国空军必须基于当时粗糙的雷达信号来做决策以决定是否派战斗机升空拦截德国轰炸机。当时雷达屏幕上的一个模糊点可能是横跨英吉利海峡的轰炸机,可能是随机噪声,也许是一群海鸥,也可能什么都没有。那些决策的人面临的第一大难题:to防or not to防是个深奥的哲学问题,深奥的哲学问题通常都可以由简单地数学问题来解决,这时候二项分类法正式踏上舞台。用白话说,做决策的人只有两种可能得决定可以做:拦截,不拦截。决定拦截,有很大的可能会浪费宝贵的油和各种资源,对本来就紧张的资源雪上加霜;决定不拦截,可能的代价是德军的飞机可能在完全无防守的状态下长驱直入,造成大量的伤亡和损失。人们需要做的是根据雷达的图像和历史数据找出一个决定是否升空拦截的最有效的算法,使得决策的结果损失最小化。
对于雷达上显示的模糊点,我们想知道的是这个点是轰炸机或者不是轰炸机两种可能,让我们暂且把这两个可能性命名为a) 轰炸机和 b) 海鸥。
我们做出的决策也有两种可能:c) 拦截, d) 不拦截。
这时候就出现了四种可能得结果:e)轰炸机来了决策拦截,简称来拦;f)轰炸机来了决策不拦截,简称来却不拦;g)轰炸机没来决策拦截,简称不来却拦,h)轰炸机没有来决策不拦截,简称不来不拦。如表1所示。其中单次事件后果最严重的可能是f,而如果g的数量如果太大也会造成巨大的损失,我们的目的是在这二者之间找一个平衡点来做出最佳决策。

表1 轰炸机和海鸥决策表
如果我们能准确预测轰炸机,那么结果则不是e就是h,那是完美的世界。
面对一个不完美的世界,我们应该如何决策使得综合损失最小?
考虑两种极限情况:
1)我们升空拦截所有可疑的点,那么我们就完全排除了来却不拦的灾难性后果,代价则是大量的虚耗
2)我们完全不管所有可疑的点,我们就完全排除了不来却拦的可能性,代价是可能被炸翻
我们知道,在雷达显示图像中,图像的面积越大,那么它是飞机的可能性越大。这给了我们把这个问题量化的机会。
假设出现20次可疑图像,我们可以把图像按照面积大小排序,见表2。假设有三个是轰炸机(标记成红色),剩下17个不是轰炸机。
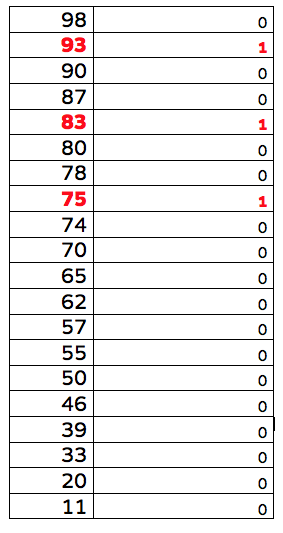
表2:雷达图面积大小排序和轰炸机的数量
在表2中,我们可以做几个试验,1)如果阈值定在90,那我们将会被无防备轰炸2次,错报2次,2)如果阈值定在80,那我们将会被无防备轰炸1次,错报4次,3)如果阈值定在75,则是0次无防备轰炸,错报5次。4)如果阈值定在60,则是0次无防备轰炸,错报9次。如表三所示
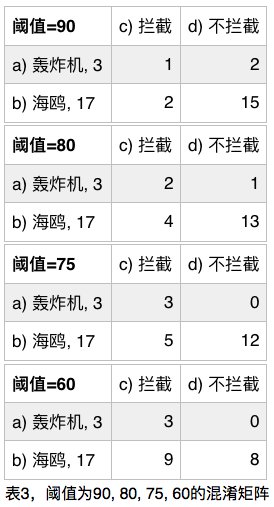
现在我们的问题缩小到如何找出合适的阈值判断是非决定升空拦截,如果单次来却不拦事件和不来却拦的损失是相同的,换句话说,如果一次无防备轰炸跟一次拦截海鸥行动造成的损失是一样的,那么我们自然是选取e跟h合起来最大的数,但是很明显被炸一次和飞机出去遛个弯儿造成的损失是不同的,而这个损失的数额则大致可以通过历史数据来得出被炸一次损失多少钱和飞一次要花多少钱。假设单次来却不拦损失1千万英镑,单次不来却拦损失400万。
至此,设定阈值后,我们知道了计算总的损失需要的四个数据,f)来却不拦次数,g)不来却拦次数,i)单次来却不拦损失, j)单次不来却拦损失。总损失除以事件发生的总次数(20次),就可以算出每个阈值设定造成的总的损失,我们需要做的就是找出这个损失的最小值。在设置成某个阈值的情况下,每次事件的平均损失计算。
平均损失= (f * i + g * j)/20
在前面的三个实验中:
1)阈值90,平均损失=(2*10,000,000 + 2* 4,000,000)/20= 140万
2)阈值80,平均损失=(1*10,000,000 + 4* 4,000,000)/20= 130万
3)阈值75,平均损失=(0*10,000,000 + 5* 4,000,000)/20= 100万
4)阈值60,平均损失=(0*10,000,000 + 9* 4,000,000)/20= 180万
总结一下概念:二项分类系统要求决策的条件是可分等级排序的,通过我们就可以决定一个阈值。所有阈值和阈值之上的事件我们称之为确定的事件,阈值之下的事件成为否定的事件,阈值的决定取决于总开销。
二项分类法中,在选取不同阈值的时候会对混沌矩阵里面各种不同的数值产生影响,我们一方面可以通过调整阈值了解最后的损失是多少,另一方面可以通过调整损失来选择阈值。我们决定阈值大小的基本数学需求就是让事件e)和 h)在四种可能情况中占的比例尽量的大,有个名字叫做ROC曲线(Receiver operating characteristic). 理解了这个基本原理,在各种不同的运用下,我们就可以用各种数学工具来调整系统的各个参数来达到最终的目的。
说完了故事,来看看这个理论在实际中的应用。
首先来看看专业知识+统计学的组合,在医学上人们常常通过检查血液中某项物质含量的指标来诊断患者是否可能患有某种疾病,唐氏综合症为例,技术是无法100%诊断胎儿是否患有该疾病。
1)根据历史数据我们可以知道某个地区患病的比例,2010年的数据,全球唐氏综合症患病概率大约是1/1000
2)我们大致知道血液中某项物质含量的指标越高,得病的可能性越大,如果我们队10000人进行采样,然后按照该物质含量进行排序,我们可以决定从哪一个含量标准开始我们分类为有风险建议用更精密手段检查,假定这个数字是1800
3)根据我们选择的阈值1800,1万人当中我们宣布1800人有风险,8200人无风险。
4)通过更精密的手段检查的时候确定1800人当中有9人时真的阳性。表4是各个数据的综合
5)这里我们同样可以估计每次发生两种错误的风险,运用前文中轰炸机和海鸥的方法来计算总成本和平均成本来确定应该把阈值定在哪里。

这个检测中我们找出了十个患病者当中的9个,这个测试并不算太优秀,也不算太差。这个数值是已知会得病的情况下,该测试者被查出来是阳性的概率,P(阳性|患病)=90%, 混淆矩阵里面叫真阳性率(true positive rate)。然而这个数据可能是医生关心的事情,个人感兴趣的是当被诊断出来是有风险的时候,有多大患病的概率,也就是P(患病|有风险) = 9/1800=0.5%,另一个对于个人有意义的数据是P(阴性|无风险) =8109/8200=98.9%. 对于医生来说,阈值的选择就会影响他告诉首测者根据历史经验受测者根据结果判断得病的概率。
而这个计算可以用简单地贝叶斯分类得出结论,这里不展开说了,大致就是如果知道事件B的发生导致事件A的发生的概率,那么我们就可以算出当事件A发生时事件B发生的概率。数学公式推导如图2所示。
这一套二项分类法几乎可以运用于所有数据分析领域应用。了解了这个统计学原理,我们就可以来看看第二个组合,统计学+程序开发能力,就形成了现代的机器学习(machine learning). 这个部分下次补上。
由于统计学很多理论是反直观的,没有统计学理论做基础,行业知识+程序开发能力的组合则是一个极端危险危险区域,常常会在数据分析上出根本性的错误。
稍微提一下我们如何使用编程+统计+行业知识做数据分析,我们在开发一套线上系统用于招聘过程的筛选,
1)每个通过这个系统的人系统会根据测试的结果和其他多方位信息综合打分,这个分数是可排序的,我们选择一个阈值来决定是让一个人走到下一步
2)招聘的流程最后的步骤会决定那些人可以获得职位。
第一个分类:系统决定某一个人是否合格,第二个分类:某一个人是否被录取。
通过多次对比两组数据我们可以预测出我们系统准确判断的概率,我们系统开发feature的改动是否能提高准确率,降低开销。
关于这部分,有时间展开细说。
!!!